Merci pour l’article, ça m’intéresse particulièrement comme j’ai eu à utiliser des algos de machine learning assez régulièrement.
Dans mon domaine, ça tend à se développer, mais ça ne surperforme pas systématiquement d’autres méthodes.
Pour expliquer un peu le type de problèmes que j’ai à traiter :
On a une base d’assurés avec des données (âge, sexe, type d’assurance, ville, enfin tout un tas d’infos, et le montant éventuels de sinistres et leur nombre), et le but est de proposer un tarif, et donc de prévoir grosso modo le montant des sinistres.
Autre cas très classique : les données des clients d’une banque, et savoir si le client est en mesure de rembourser un prêt.
Là où ça devient intéressant, c’est de voir la performance des modèle, pour se faire on créer une base d’apprentissage sur laquelle le modèle est calibré, et une base sur laquelle on va tester le modèle.
Car évidement il ne suffit pas que le modèle soit bon sur la base d’apprentissage, mais il faut voir sa perf sur des nouvelles données.
Et c’est là où l’on peut avoir des problématiques intéressantes.
Par exemple, typiquement, une banque a souvent une base de donnée avec 99% de bons payeurs, donc un programme qui si on lui donne un client dirait à 100% du temps qu’il s’agit d’un bon payeur n’aurait qu’1% d’erreur ce qui est très faible, pourtant l’algo est complètement inutile.
Donc là on a des problèmes intéressants : comment faire pour que l’algo apprenne spécifiquement les mauvais payeurs ? Alors on trouve des solutions, mais souvent ça coûte cher en terme d’erreur.
Donc après on a d’autre problématiques : ça coûte combien de refuser un prêt alors que la personne est capable de rembourser ? Ca coûte combien d’en accepter un alors que la personne ne remboursera pas ?
Même chose en médecine : on va avoir une population saine, et par exemple 0.5% de malade d’un cancer.
Ca coûte quoi de diagnostiquer un cancer à quelqu’un qui n’en a pas ? Et de ne pas en diagnostiquer un quand la personne en a effectivement un ?
Quel taux de faux positif est acceptable ? Quel taux de faux négatifs ?
Autre problématique : le surapprentissage, en fait plus le modèle est complexe moins il va être bon quand on va lui donner de nouvelles données.
Ca c’est un des gros points sur lesquels on doit veiller quand on travaille avec des modèles de réseaux de neurones, notamment bien calibrer le nombre de pas d’apprentissage, le nombre de couches cachées, etc.
Les images sont plus parlantes :

Typiquement ici on cherche un modèle qui distingue les points bleu des points rouge, et le modèle vert overfit : il colle trop aux données qu’on lui a fourni donc là OK il aura une erreur plus faible sur ces données, mais sera sûrement moins bon si on collecte de nouvelles données.
Même chose ici :
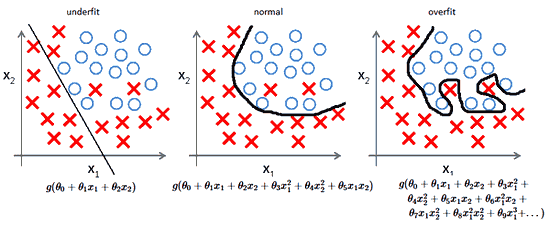
Le deuxième modèle est sûrement le meilleur, même si sur notre base on voit qu’il classe mal deux points, alors que le troisième ne fait aucune erreur, il risque d’être moins bon sur de nouvelles données.
Et dernier exemple, un peu grotesque, c’est probablement un modèle polynomiale ici :
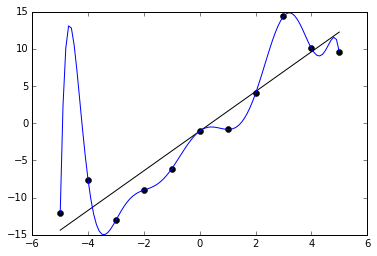
Le modèle bleu n’a aucune erreur alors que le modèle noir a un petit pourcentage d’erreur, mais c’est très clair que le bleu ne sera pas robuste ici.
Enfin pour finir sur le sujet, j’ai participé à quelques compétitions sur le net, ça se développe, et c’est vraiment très intéressant, il y a de tout :
Par exemple prévoir les résultats au basket (lol) :
guérir le cancer :
Les récompenses sont conséquentes (souvent plusieurs dizaines de milliers de dollars), mais les mecs qui les font sont souvent très bons.
Il faut le matos (parfois mon pc n’est même pas capable de lire la base de données tellement elle est énorme, donc impossible de calibrer quoique ce soit).
Et parfois, je regarde le code des équipes qui ont fait de bonnes places (oui ils partagent leur code après la compétition parfois!). L’autre jour, en 3 éme place, une équipe composée de 6 docteurs en maths et 2 data scientists, donc impossible à concurrencer ahah :D.
 .
.
